今天小編分享的科技經驗:蘋果也發布了自己的大模型,這是一件影響深遠 的大事,歡迎閱讀。
剛剛過去的周末,蘋果發表了一篇論文,公布了自己研發的 MM1 多态大語言模型 ( Multimodal LLM ) 。這注定是人工智能發展史上的又一個标志性事件!很遺憾,我不是技術研發人員,對這篇論文只能粗略看懂一些基本信息。我的一些從事大模型研發的朋友,昨天已經徹夜不眠地進行深度研究了。
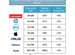
蘋果這次公布的 MM1 大模型分為三個參數規模,其中最大的擁有 300 億參數,與市面上的主流競品相比,好像不是很大——要知道,谷歌 PaLM 大模型擁有 5400 億參數,OpenAI 的 GPT-4 更是擁有 1.7 萬億參數(注:OpenAI 官方并未披露參數數量,僅有外界猜測)。科技博客 Daily Dev 的評測顯示,MM1 在 GLUE-Score 等多項評測指标上要略優于 GPT-4V 和 Gemini Pro;不過眾所周知,這種評測的參考價值有限。MM1 目前還沒有公測,官方也沒有公布上線時間表,要評估其具體的技術水平可能還需要很長一段時間。
蘋果發表的 MM1 大模型論文的标題和作者列表

對于人工智能行業乃至全球科技行業而言,MM1 大模型本身可能是一件小事,蘋果由此表現出的姿态則是一件大事。具體而言:
蘋果今後肯定會依賴自研大模型,而不是 OpenAI 等第三方的大模型或者開源大模型。大模型是一項基礎設施,沒有哪個科技巨頭願意受制于人,都會投入盡可能多的資源實現自主。今後大模型賽道的競争會更激烈。
根據蘋果一貫的作風,它肯定想實現 " 軟體 - 算法 - 芯片 " 三位一體的統一,今後肯定會建立自己的 AI 開發社區,甚至在芯片領網域挑戰一下英偉達。AMD 和英特爾都沒有這個實力,但蘋果确實有一定希望。
在長期,最值得關注的話題是:蘋果會不會走邊緣計算、本地化推理的路線?這将直接決定 "AI 手機 " 有沒有市場。不過這個問題不是一兩年内能解決的。
先說第一條。在 ChatGPT 剛剛發布時,業界的主流觀點是:世界上不需要那麼多大模型,可能只需要 3-5 個,包括 1-2 個最先進的閉源大模型,再加上幾個開源大模型。現在的情況卻是人人都想做自己的大模型。此前很長一段時間,大家都覺得蘋果是一家消費電子廠商,沒有必要押注于自研大模型,只需要租用市面上最先進的大模型就可以了。現實告訴我們,蘋果不是這麼想的。就像我的一位從事大模型研發的朋友所說:"AGI 時代,自己有控制權的大模型才是最好的。OpenAI 不可能将模型參數開放給蘋果,蘋果也不會樂意受制于微軟生态。不管它做不做得好,它只能自己做!"
如果蘋果是這麼想的,其他科技巨頭就更會這麼想了。谷歌和亞馬遜都投資了 Anthropic(除了 OpenAI 之外最炙手可熱的 AI 創業公司),Salesforce 投資了 Mistral;各家大廠收購的小型研發團隊就更是數不勝數了。無論這個世界究竟需要多少大模型,每個科技巨頭都會做自己的大模型,而且肯定不止做一個——内部孵化幾個、外部投資或并購幾個,才是常态。
前一段時間,市場上有消息稱,蘋果從鴻海訂購了 2 萬台 AI 伺服器,其中 40-50% 是英偉達 H100 伺服器。當時很多人(包括我在内)認為這些伺服器主要是用來推理的,不過用 H100 推理顯得過于奢侈了。現在看來,這些伺服器應該既包括推理需求、也包括訓練需求。蘋果最不缺的就是錢,既然它決定了押注自研大模型,就一定會把戰争打到底。全球 AI 算力緊缺的局勢看樣子會雪上加霜。
再說第二條。雖然外界經常低估蘋果的研發實力,但是在歷史上,蘋果經常通過在消費產品積累的資源去進軍中上遊、直至切入核心技術層面,這一點在民用芯片領網域體現的最明顯:自從 2021 年以來,蘋果自研的 M 系列芯片已經全面替代英特爾 x86 芯片,成為 Mac 電腦的标配,乃至被 " 下放 " 到了 iPad 當中。一位熟悉這個領網域的朋友告訴我:" 蘋果絕不會甘願受制于 CUDA。它熱衷于獨立掌握核心算法,對自研芯片進行适配優化,從而實現芯片 - 算法 - 軟體的整合。不過它一定會小心謹慎地行事。"
眾所周知,英偉達依托 CUDA 生态,建立了牢不可破的競争壁壘。但是,英偉達的驅動程式并不開源(注:有極少數開源過,但于事無補),CUDA 也并不好用。AMD、英特爾等競争對手已經被甩出太遠了,依靠它們去挑戰英偉達并不顯示。蘋果則擁有這樣的實力,看樣子也擁有這樣的意願。不過,就算它決定進軍英偉達的地盤,這個過程也會持續相當漫長的時間——要知道,從 2006 年 Mac 換用英特爾芯片到 2020 年轉向自研芯片,經過了整整 14 年!

附帶說一句,哪怕英偉達的競争對手(無論是不是蘋果)成功地奪走了一些市場份額,也不會解決當前 AI 算力緊缺的問題,因為瓶頸主要在制造環節。尤其是訓練相關的芯片制造,在未來很長一段時間内估計還是台積電的天下。無論誰是 AI 芯片的王者,它都要依賴台積電代工。這是一個工程問題,只能循序漸進地解決。
最後,今後的 AI 推理主要在雲端(數據中心)還是終端(手機、電腦)實現,這是一個争議很大的話題。我們看到各家手機廠商在争先恐後地推出 "AI 手機 " ——很可惜,這些產品現在還沒什麼用,消費者沒有任何迫切的需求。當年的雲遊戲概念,是希望把遊戲算力從終端搬到雲端;現在的 AI 手機概念,則是希望把推理算力從雲端搬到終端。前者已經被證明不切實際(至少現在是如此),後者則前途未卜。
作為全球最大、最賺錢的智能終端廠商,蘋果肯定會希望終端多承擔一些 AI 推理職責,這也有助于 iOS 生态的進一步擴張。然而,技術進步不會以任何科技巨頭的主觀願望為轉移。很多人猜測,蘋果大模型的研發方向将指向邊緣計算、本地化和小型化,其戰略目标是開發出适合在移動端本地推理的模型。但是從目前的公開信息(主要就是那篇論文)中,我們尚不能獲得足夠的信息。
對于蘋果的投資者而言,最大的好消息是:蘋果注意到了自研大模型的重要性,不甘于在這個戰略性賽道上掉隊,而且正在試圖利用自身資源禀賦去影響大模型技術的發展方向。資本市場可能會對此做出良好的反應(尤其是考慮到今年以來蘋果衰落的股價),但是能否實現又是另一回事了。