今天小編分享的科技經驗:大模型無限流式輸入推理飙升46%,國產開源加速「全家桶」,打破多輪對話長度限制,歡迎閱讀。

Colossal-AI 團隊開源了 SwiftInfer,基于 TensorRT 實現了 StreamingLLM,可以進一步提升大模型推理性能 46%,為多輪對話推理提供了高效可靠的落地方案。
大模型推理再次躍升一個新台階!最近,全新開源的國產 SwiftInfer 方案,不僅能讓 LLM 處理無限流式輸入,而且還将推理性能提升了 46%。
在大型語言模型(LLM)的世界中,處理多輪對話一直是一個挑戰。前不久麻省理工 Guangxuan Xiao 等人推出的 StreamingLLM,能夠在不犧牲推理速度和生成效果的前提下,可實現多輪對話總共 400 萬個 token 的流式輸入,22.2 倍的推理速度提升。
但 StreamingLLM 使用原生 PyTorch 實現,對于多輪對話推理場景落地應用的低成本、低延遲、高吞吐等需求仍有優化空間。
Colossal-AI 團隊開源了SwiftInfer,基于 TensorRT 實現了 StreamingLLM,可以進一步提升大模型推理性能 46%,為多輪對話推理提供了高效可靠的落地方案。
開源地址:https://github.com/hpcaitech/SwiftInfer
StreamingLLM 簡介
大語言模型能夠記住的上下文長度,直接影響了 ChatGPT 等大模型應用與用戶互動的質量。
如何讓 LLM 在多輪對話場景下保持生成質量,對推理系統提出了更高的要求,因為 LLM 在預訓練期間只能在有限的注意力視窗的限制下進行訓練。
常見的 KV Cache 機制能夠節約模型計算的時間,但是在多輪對話的情景下,key 和 value 的緩存會消耗大量的内存,無法在有限的顯存下無限擴展上下文。
同時,訓練好的模型在不做二次微調的前提下也無法很好地泛化到比訓練序列長度更長的文本,導致生成效果糟糕。

來源:https://arxiv.org/pdf/2309.17453.pdf
StreamingLLM 為了解決了這個問題,通過觀察了注意力模塊中 Softmax 的輸出,發現了 attention sink 的現象。
我們知道注意力機制會為每一個 token 分配一個注意力值,而文本最初的幾個 token 總是會分配到很多無用的注意力。
當我們使用基于滑動視窗的注意力機制時,一旦這幾個 token 被踢出了視窗,模型的生成效果就會迅速崩潰。但只要一直把這幾個 token 保留在視窗内,模型就能穩定地生成出高質量的文本。
比起密集注意力(Dense Attention)、視窗注意力(Window Attention)以及帶重計算的滑動視窗注意力 ( Sliding Window w/ Re-computing ) ,StreamingLLM 基于 attention sink 的注意力機制無論是在計算復雜度還是生成效果上都表現優異。
在不需要重新訓練模型的前提下,StreamingLLM 能夠直接兼容目前的主流大語言模型并改善推理性能。
SwiftInfer:基于 TensorRT 的 StreamingLLM 實現
為了将 StreamingLLM 這一技術更好的應用到落地場景,Colossal-AI 團隊成功地将 StreamingLLM 方法與 TensorRT 推理優化結合,不僅繼承了原始 StreamingLLM 的所有優點,而且還具有更高的運行效率。
此外,使用 TensorRT-LLM 的 API,還能夠獲得接近于 PyTorch API 的模型編寫體驗。 基于 T ensorRT-LLM,團隊 重新實現了 KV Cache 機制以及帶有位置偏移的注意力模塊。
如下圖所示,假設視窗大小為 10 個 token,随着生成的 token 增加(由黃色方塊表示),我們在 KV 緩存中将中間的 token 踢出,與此同時,始終保持着文本開始的幾個 token(由藍色方塊表示)。 由于黃色方塊的位置會發生變化,在計算注意力時,我們也需要重新注入位置信息。

需要注意的是,StreamingLLM 不會直接提高模型能訪問的上下文視窗,而是能夠在支持流式超多輪對話的同時保證模型的生成效果。
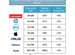
大模型無限輸入流推理加速 46%
原版本的 StreamingLLM 可以可靠地實現超過 400 萬個 token 的流式輸入,實現了比帶重計算的滑動視窗注意力機制高出 22.2 倍的速度提升。
Colossal-AI 團隊發布的 SwiftInfer 可以進一步提升推理性能,最多帶來額外的最多46% 的推理吞吐速度提升,為大模型多輪對話推理提供低成本、低延遲、高吞吐的最佳實踐。TensorRT-LLM 團隊也在同期對 StreamingLLM 進行了類似支持。

Colossal-AI 社區動态
Colossal-AI 目前已獲得 GitHub 星數三萬五千多顆,位列全球 TOP400,細分賽道排名世界第一,可通過高效多維并行、異構内存等,降低 AI 大模型訓練 / 微調 / 推理的開發與應用成本,提升模型任務表現,降低 GPU 需求。作為主流開源 AI 大模型系統社區,Colossal-AI 生态在多方面保持活躍更新。

Colossal-LLaMA-2-13B 開源
Colossal-LLaMA-2-13B 模型,僅用 25B token 數據和萬元算力,效果遠超基于 LLaMA-2 的其他中文漢化模型。
即使與其他采用中文語料,可能花費上千萬元成本,從頭預訓練的各大知名模型相比,Colossal-LLaMA-2 在同規模下仍表現搶眼。
13B 版本通過構建更為完善的數據體系,在知識性内容掌握程度,自然語言處理任務理解程度,以及安全性,價值觀等問題上,都有質的提升。

Colossal-AI 雲平台
Colossal-AI 雲平台在整合 Colossal-AI 系統優化和廉價算力的基礎上,近期發布了 AI 雲主機的功能,方便用戶以近似裸機的方式進行 AI 大模型的開發和調試,并提供了多種使用方式,包括:Jupyter Notebook、ssh、服務本地端口映射和 grafana 監控,全方位的為用戶提供便捷的開發體驗。
同時,還為用戶預制了含有 ColossalAI 代碼倉庫和運行環境的 docker 鏡像,用戶無需環境和資源配置,便可一鍵運行 ColossalAI 代碼倉庫中的代碼樣例。