今天小編分享的科技經驗:英偉達發布最強 AI 加速卡--Blackwell GB200,今年發貨,歡迎閱讀。
IT 之家 3 月 19 日閃訊速報,英偉達發布最強 AI 加速卡 --Blackwell GB200,今年發貨。
英偉達在今天召開的 GTC 開發者大會上,正式發布了最強 AI 加速卡 GB200,并計劃今年晚些時候發貨。


GB200 采用新一代 AI 圖形處理器架構 Blackwell,黃仁勳在 GTC 大會上表示:"Hopper 固然已經非常出色了,但我們需要更強大的 GPU"。

英偉達目前按照每隔 2 年的更新頻率,更新一次 GPU 架構,從而大幅提升性能。英偉達于 2022 年發布了基于 Hopper 架構的 H100 加速卡,而現在推出基于 Blackwell 的加速卡更加強大,更擅長處理 AI 相關的任務。
Blackwell GPU
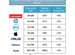
黃仁勳表示,Blackwell 的 AI 性能可達 20 petaflops,而 H100 僅為 4 petaflops。Nvidia 表示,額外的處理能力将使人工智能公司能夠訓練更大、更復雜的模型。

Blackwell GPU 體積龐大,采用台積電的 4 納米(4NP)工藝蝕刻而成,整合兩個獨立制造的裸晶(Die),共有 2080 億個晶體管,然後通過 NVLink 5.0 像拉鏈一樣捆綁芯片。


英偉達表示每個 Blackwell Die 的浮點運算能力要比 Hopper Die 高出 25%,而且每個封裝中有兩個 Blackwell 芯片,總性能提高了 2.5 倍。如果處理 FP4 八精度浮點運算,性能還能提高到 5 倍。取決于各種 Blackwell 設備的内存容量和帶寬配置,工作負載的實際性能可能會更高。
英偉達使用 10 TB / sec NVLink 5.0 連接每塊 Die,官方稱該鏈路為 NV-HBI。Blackwell complex 的 NVLink 5.0 端口可提供 1.8 TB / 秒的帶寬,是 Hopper GPU 上 NVLink 4.0 端口速度的兩倍。
GB200
英偉達表示 GB200 包含了兩個 B200 Blackwell GPU 和一個基于 Arm 的 Grace CPU 組成,推理大語言模型性能比 H100 提升 30 倍,成本和能耗降至 25 分之一。
Nvidia 聲稱,訓練一個 1.8 萬億個參數的模型以前需要 8000 個 Hopper GPU 和 15 兆瓦的電力。如今,Nvidia 首席執行官表示,2000 個 Blackwell GPU 就能完成這項工作,耗電量僅為 4 兆瓦。
在參數為 1,750 億的 GPT-3 LLM 基準測試中,Nvidia 稱 GB200 的性能是 H100 的 7 倍,而訓練速度是 H100 的 4 倍。

英偉達還面向有大型需求的企業提供成品服務,提供完整的伺服器出貨,例如 GB200 NVL72 伺服器,提供了 36 個 CPU 和 72 個 Blackwell GPU,并完善提供一體水冷散熱方案,可實現總計 720 petaflops 的 AI 訓練性能或 1,440 petaflops(又稱 1.4 exaflops)的推理性能。它内部使用電纜長度累計接近 2 英裡,共有 5000 條獨立電纜。

機架上的每個托盤包含兩個 GB200 芯片或兩個 NVLink 交換機,每個機架有 18 個 GB200 芯片和 9 個 NVLink 交換機,英偉達稱,一個機架總共可支持 27 萬億個參數模型。而作為對比,GPT-4 的參數模型約為 1.7 萬億。
該公司表示,亞馬遜、谷歌、微軟和甲骨文都已計劃在其雲服務產品中提供 NVL72 機架,但不清楚它們将購買多少。
英偉達表示亞馬遜 AWS 已計劃采購由 2 萬片 GB200 芯片組建的伺服器集群,可以部署 27 萬億個參數的模型。
Nvidia 也樂于為公司提供其他解決方案。下面是用于 DGX GB200 的 DGX Superpod,它将八個系統合而為一,總共擁有 288 個 CPU、576 個 GPU、240TB 内存和 11.5 exaflops 的 FP4 計算能力。

英偉達稱,其系統可擴展至數萬 GB200 超級芯片,并通過其新型 Quantum-X800 InfiniBand(最多 144 個連接)或 Spectrum-X800 以太網(最多 64 個連接)與 800Gbps 網絡連接在一起。
英偉達目前并未公布 GB200 以及整套方案的售價信息。